M&M Problem, Part II: The Likelihood
Overview
Teaching: 0 min
Exercises: 0 minQuestions
What is the likelihood for the fraction of blue M&Ms?
Objectives
First learning objective. (FIXME)
In the last few episodes, we have talked about probabilities, Bayes’ rule and probability distributions. Then we have set up our M&Ms research question.
It is now time to put our new knowledge to work!
Let’s remind ourselves of Bayes’ rule:
Bayes’ rule
We would like to estimate , the number of blue M&Ms produced at the factory. To do that, we need to figure out the two terms on the right-hand side:
- the likelihood,
- the prior probability,
In this episode, we’re going to talk about the likelihood.
The likelihood describes the probability of observing a certain data set, given that we assume a model to be true. Let’s assume we know that the true fraction of blue M&Ms produced at the factory is 0.5, so half of all M&Ms that are being produced will be blue. What can we say about the number of M&Ms?
Number of blue M&Ms per bag
Imagine that you had 10 bags with 50 M&Ms each. What will the number of M&Ms be in each bag? Will it always be the same?
What could affect whether the number of M&Ms in each bag might be the same, or different?
Solution
The number of blue M&Ms per bag will only be the same in each bag if that number is carefully counted out before the bags are mixed. In practice, that seems unlikely, because it would produce a lot of extra work. It is more likely that there’s a huge box of M&Ms of all colours, and a machine scoops out a handful of them into a bag.
This means we do not expect the number of M&Ms to be the same in each bag. However, we expect that if we open many bags, then on average 50% of all the M&Ms we counted should be blue.
The likelihood tells us how we go from the known fraction of M&Ms, , to the number of blue M&Ms per bag. But what equation do we need to write down to do this?
Let’s first start with our actual observables, i.e. the things we can measure about a bag of M&Ms. As we’ve said before, we assume we only have two colours: blue and not-blue. Like all models, this is a simplification of reality, but if we only care about the blue M&Ms, that’s okay. If we suddenly also cared about the green M&Ms, we would have to make our model more complicated (if you’re truly curious, the last episode in this lesson, on Bayesian hierarchical modelling, also tackles that question).
In practice, there are two numbers we measure: the number of blue M&Ms, let’s call those , and the number of not-blue M&Ms, . Because those are the only two possible outcomes of drawing an M&M out of the bag, together they make up the total number of M&Ms in the bag, $N$.
Every time you draw an M&M out of a bag, you get one of two outcomes: blue or not-blue. In a more statistical language, a draw of an M&M out of a bag is called a trial, drawing a blue M&M is called a success (a not-blue M&M is called a failure). You can do this $N$ times and then record the number of successes, $k$.
Let’s assume that there’s an underlying fraction that are produced at the factory. What’s the probability of drawing a blue M&M out of the bag? Well, it’s just . Because our set-up only has two outcomes, and probabilities must sum to 1, the probability of having a not-blue M&M is therefore .
So what’s the probability of drawing a blue M&M, followed by a not-blue M&M? This will be the joint probability of first drawing a blue M&M, and then drawing a not-blue M&M, which can be written as
So we’ve just multiplied the probability for getting a blue M&M with the probability of getting a not-blue M&M. In the equation above, is just a placeholder for the blue + not-blue sequence we just described.
Exercise
What is the probability of the sequence: b b n n n b n ?
Solution
Like in the example above, we can string together the probabilities:
For any given sequence of draws out of the bag, we can write down the probability of that sequence as the product of the probabilities for each of the individual draws. So for a sequence with blue M&Ms, not-blue M&Ms and therefore a total M&Ms, we can write the probability of that exact sequence as
That’s great, you might say, we’re done! We know what the probabiity is! However, there is one crucial element missing! This probability tells you the probability of that exact sequence. But if we pour the contents of a bag of M&Ms onto the table, then what? Have we first drawn a blue M&M? A not-blue M&M? Will it depend on whether we draw a blue or not-blue M&M first? It shouldn’t. The probability of the sequence “b n b” is the same as for the sequence “b b n” and also for the sequence “n b b”. The equation above doesn’t account for that, so we need an extra factor that adjusts the probability for the fact that I could have drawn any of those three sequences. This factor is , pronounced “n choose k” and also called the binomial coefficient. It can be written out as
The “!” symbol is called a “factorial”, and short-hand for writing out a product of all the numbers from that number to 1 (note that ). This fraction is the adjustment you need to do to make sure you don’t count “n b b”, “b n b” and “b b n” as separate cases.
Exercise: Binomial factors
Convince yourself for the three-outcome case that the binomial factor accurately adjusts the probability.
Solution
In the above case, we have three possible sequences we could draw. For each sequence, the probability is
We want to know the probability that any of those sequences happen, which we can calculate by summing together the probability for each of the three outcomes (which is the same as multiplying the probability above by . Can we use the binomial coefficient to arrive at the same answer?
Therefore, the probability of having two blue M&Ms and one not-blue M&M in any set of three M&Ms is
We now have all the ingredients to write down the probability of getting any set of blue M&Ms in a set of total M&Ms:
Binomial Probability Distribution
This is also called the binomial distribution, and will serve as our likelihood.
The Binomial Distribution in Python
It is instructive to take a look at the shape of the binomial distribution for a number of different cases. Let’s try and write some code to do that.
First, we’ll need a function that can calculate the binomial distribution:
def binomial_distribution( ## ADD PARAMETERS HERE ## ):
## ADD YOUR FUNCTION HERE
## HINT: scipy.special.comb is useful for
## calculating (n choose k)
## don't forget to include a string that explains the
## input variables and the output for future users!
return prob
Exercise
What parameters do you think the function above should take?
Can you fill out the code in the function to return the binomial probability?
Solution
Here’s an implementation of the binomial distribution:
def binomial_distribution(n, k, q): """ Calculate the probability of $k$ successes out of $n$ trials, given an underlying success rate $q$. Parameters ---------- n : int The total number of trials k : int The number of successful draws out of $n$ q : float, [0,1] The success rate Returns ------- prob : float [0,1] The binomial probability of $k$ draws out of $n$ trials """ bin_fac = factorial(n)/(factorial(k) * factorial(n-k)) first_prob = q ** k second_prob = (1. - q) ** (n - k) prob = bin_fac * first_prob * second_prob return probNote: it would be very time-consuming if we hat to code up all of our probability distributions all the time! Thankfully, the helpful open-source developers working on
scipyhave done this work for us! Theyscipy.statsmodule implements a large range of probability distributions.For example, we could achieve the same as above:
import scipy.stats prob = scipy.stats.binom(n=n, p=q).pmf(k)Here,
pmfstands for “probability mass function”, which is what probability distributions for discrete outcomes are called.
This function allows us to calculate the probability distribution, also called the probability mass function for problems that have discrete outcomes (in our case we can only have integer outcomes, i.e. 1 blue m&m, or 2 blue m&ms, etc.).
Let’s do another exercise:
Plotting the Probability Mass Function
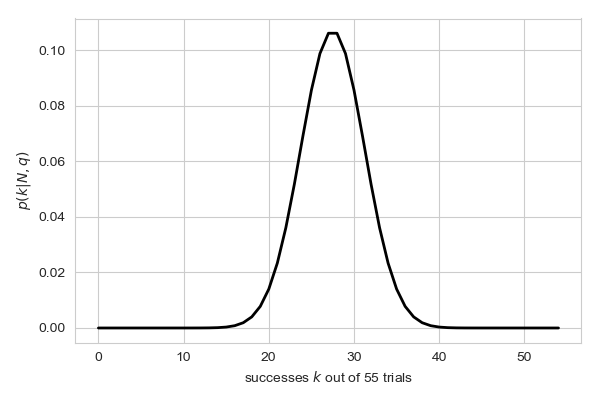
Imagine we have a bag with 55 M&Ms. Our friend, who works at the M&M factory, has told us that 50% of all M&Ms should be blue. Plot the probability mass function for different values of . Which value of has the largest probability?
Solution
Let’s write a loop that runs through all possibilities, from no blue M&Ms at all to every M&M is blue:
n = 55 # total number of M&Ms q = 0.5 # fraction of blue M&Ms at the factory # generate a list of all possible values of k, going # from 0 to 55 ktrial = np.arange(0, n, 1) # make a list of zeros to store the probabilities for # each value of k in prob = np.zeros(n) # loop through all values of k and calculate the binomial probability # for this case for i,k in enumerate(ktrial): prob[i] = binomial_distribution(n, k, q) # plot the results fig, ax = plt.subplots(1, 1, figsize=(6,4)) ax.plot(ktrial, prob, lw=2, color="black") ax.set_xlabel(r"successes $k$ out of %i trials"%n) ax.set_ylabel(r"$p(k|N,q)$") plt.tight_layout()This is what our output should look like:
So you should see somewhere between 25 and 35 in a bag of 55 M&Ms fairly often, but extreme values (e.g. only 5 blue M&Ms, or 50 blue M&Ms) very, very rarely.
Key Points
First key point. Brief Answer to questions. (FIXME)